|
皇冠hg86a重庆时时彩色碟博彩平台用户体验评价_[[423200]]彩票现金网 Hadoop是一个由Apache基金会开采的分散式系统基础架构。开采东说念主员不错在不了解分散式底层细节的情况下开采分散式本领,充分诈欺集群的威力进行高速并交运算以及海量数据的分散式存储。Hadoop大数据时代架构如图1所示。 博彩平台用户体验评价
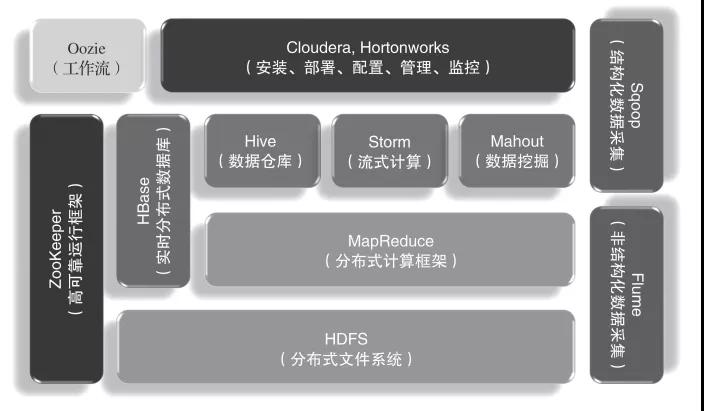
图1 Hadoop大数据时代架构 然则,Hadoop不是一个孤单的时代,而是一套齐全的生态圈,如图2所示。在这个生态圈中,Hadoop最中枢的组件便是分散式文献系统HDFS和分散式瞎想框架MapReduce。HDFS为海量的数据提供了存储,是通盘大数据平台的基础,而MapReduce则为海量的数据提供了瞎想才能。在它们之上有多样大数据时代框架,包括数据仓库Hive、流式瞎想Storm、数据挖掘器用Mahout和分散式数据库HBase。此外,ZooKeeper为Hadoop集群提供了高可靠运行的框架,保证Hadoop集群在部分节点宕机的情况下已经可靠运行。Sqoop与Flume分离是结构化与非结构化数据收集器用,通过它们不错将海量数据抽取到Hadoop平台上,进行后续的大数据分析。 记者2日从财政部了解到,财政部、国家税务总局发布多则公告,明确延续优化多项税收优惠政策。 有网友分析,龙口粉丝不能空腹服用的关键在于其成分中的绿豆是“寒性”食材,大量服用会对胃产生刺激。
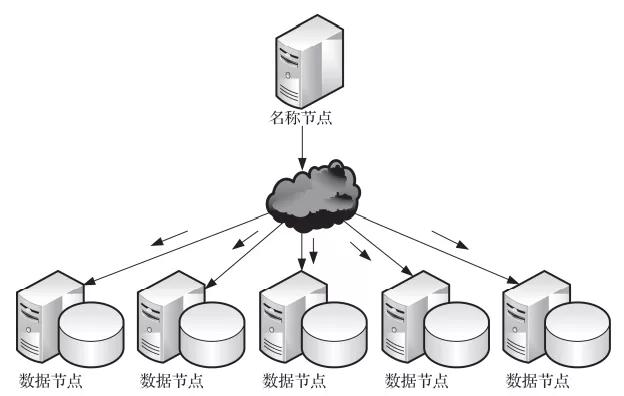
图2 Hadoop大数据生态圈 皇冠客服飞机:@seo3687Cloudera与Hortonworks是大数据的集成器用,它们将大数据时代的多样组件集成在全部,简化装配、部署等责任,并提供长入真实立、措置、监控等功能。Oozie是一个业务编排器用,咱们将复杂的大数据处理经由解耦成一个个小剧本,然后用Oozie组织在全部进行业务编排,依期实行与治疗。 数据分析 01分散式文献系统往常,咱们用诸如DOS、Windows、Linux、UNIX等许多系统来在瞎想机上存储并措置多样文献。与它们不同的是,分散式文献系统是将文献散列地存储在多个职业器上,从而不错并行处理海量数据。 Hadoop的分散式文献系统HDFS如图3所示,它领先将职业器集群分为称呼节点(NameNode)与数据节点(DataNode)。称呼节点是死亡节点,当需要存储数据时,称呼节点将很大的数据文献拆分红一个个大小为128MB的小文献,然后散列存储在其下的好多量据节点中。当Hadoop需要处理这个数据文献时,实质上便是将其分散到各个数据节点上进行并行处理,使性能得到大幅进步。
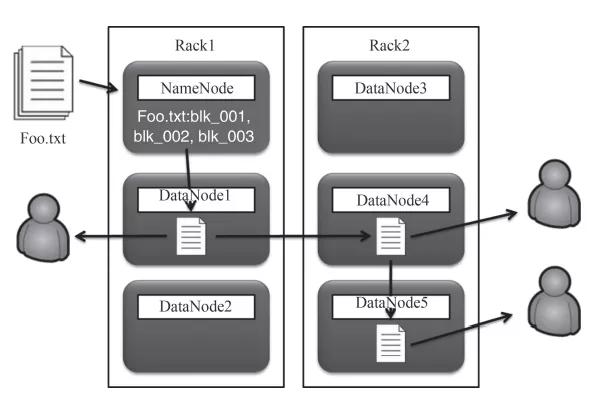
图3 分散式文献系统HDFS 体育博彩篮球分析师同期,每个小文献在存储时,还会进行多节点复制(默许是3节点复制),一方面不错并行读取数据,另一方面不错保险数据的安全,即任何一个节点失效,数据都不会丢失。当一个节点宕机时,若是该节点的数据不及3份,就会立即发起数据复制,永远保抓3节点的复制。正因为具有这么高可靠的文献存储,Hadoop的部署不需要备份,欧博线上代理也不需要磁盘镜像,在Hadoop集群的各个节点中挂载大容量的磁盘并确立Raid0就不错了。 重庆时时彩色碟 02分散式瞎想框架Hadoop的另一个枢纽组件是分散式瞎想框架MapReduce,它将海量数据的处理分散到许多量据节点中并行进行,从而提高系统的运行效果。 皇冠体育足球MapReduce瞎想词频的处理经由如图4所示。在这个经由中,领先输入要处理的数据文献,经过Splitting将其拆分到各个节点中,并在这些节点的腹地实行Mapping,将其制作成一个Map。不同的任务不错瞎想不同的Map。比喻,当今的任务是瞎想词频,因此该Map的key是不同的词,value是1。这么,在后续的处理经由中,将疏导词的1加在全部便是该词的词频了。
图4 分散式瞎想框架MapReduce Mapping操作实行完以后,就运行Shuffling操作。它是通盘实行经由中效果最差的部分,需要在各个节点间交换数据,将消亡个词的数据放到消亡个节点上。何如灵验地裁汰交换的数据量成为优化性能的枢纽。接着,在每个节点的腹地实行Reducing操作,将消亡个词的这些1加在全部,就得到了词频。临了,将分散在各个节点的收尾皆集到全部,就不错输出了。 
通盘瞎想有6个处理经由,那么为什么它的名字叫MapReduce呢?因为其他处理经由都被框架封装了,开采东说念主员只需要编写Map和Reduce经由就能完成多样万般的数据处理。这么,时代门槛裁汰了,大数据时代得以流行起来。 03优污点与传统的数据库比较,MapReduce分散式瞎想天然有无与伦比的性能上风,但并不适用于扫数场景。MapReduce莫得索引,它的每次瞎想都是“暴力全扫描”,行将通盘文献的所特地据都扫描一遍。若是要分析的收尾触及该文献80%以上的数据,与联系型数据库比较,能得到很是优异的性能。若是仅仅为了查找该文献中的某几十札记载,那么它既糜掷资源,性能也没探究系型数据库好。因此,MapReduce的分散式瞎想更合适在后台对批量数据进行离线瞎想,即一次性对海量数据进行分析、整理与运算。它并不适用于在前台面向结尾用户的在线业务、事务处理与随即查询。 同期,MapReduce更合适对大数据文献的处理,而不合适对海量小文献的处理。因此,当要处理海量的用户文档、图片、数据文献时,应当将其整合成一个大文献(序列文献),然后交给MapReduce处理。惟有这么才能充分施展MapReduce的性能。 澳门皇冠影视彩票现金网 本文摘编自《架构真意:企业级应用架构瞎想依次论与试验》,经出书方授权发布。 iba百家乐注册
|